

















Claude 开发教程笔记
本文是对 Anthropic 开发者教程 的笔记
📚 课程概述
🎯 学习目标
完成本课程后,您将掌握:
- 向 Claude 模型发送 API 请求并处理响应
- 实现多轮对话、流式传输和结构化输出生成
- 使用自动化测试流程系统地构建和评估提示词
- 创建自定义工具并将 Claude 与外部服务集成
- 设计和实现具有混合搜索和重新排序功能的 RAG 系统
- 使用 MCP(模型上下文协议)将 Claude 连接到各种数据源
- 理解常见的工作流和代理架构
📖 课程大纲
第一部分:Claude 入门
完整请求生命周期(五个阶段)
- 客户端 → 服务器:用户发起请求
- 服务器 → Anthropic API:服务器转发请求
- 模型处理:Claude 处理请求
- API → 服务器:返回响应
- 服务器 → 客户端:显示结果
⚠️ 安全提示:永远不要从客户端直接调用 API,API 密钥必须保存在安全的服务器端
API 必须参数

核心概念解析
Token(词元)
Token 是文本处理的基本单位,可以是:
- ✅ 完整的单词:
"hello" - ✅ 单词的一部分:
"running"可能被分为"run"+"ning" - ✅ 空格:词与词之间的空格
- ✅ 标点符号:
"."",""!" - ✅ 特殊字符:
"@""#""$"
Embedding(嵌入)
Embedding 是将 token 转换为数值向量的过程。这些向量能够数学化地表示词语的含义和语义关系,使计算机能够”理解”文本内容。
模型工作原理简述
1. 分词(Tokenization)
将文本分解为更小的单元(token)
2. 嵌入(Embedding)
将每个 token 转换为数值向量,表示其语义含义
3. 语境化(Contextualization)
根据上下文调整向量值,确定词语在特定语境中的确切含义
4. 生成(Generation)
计算下一个词的概率分布,结合概率和随机性选择输出,逐词生成响应
生成停止条件
Claude 在每个 token 后检查是否满足以下条件:
- 是否达到最大 token 数限制
- 是否生成了结束序列标记
- 是否遇到预定义的停止标记
Temperature 参数详解
作用
Temperature 参数用于控制模型生成时的创造性:
- 较低的 temperature:输出更加确定性和一致性,适合严谨的任务(如文本引用、数据提取)
- 较高的 temperature:输出更加多样化和创意性,适合创作性任务(如写作、头脑风暴)
工作原理
Claude 的文本生成过程包含三个关键步骤:
-
Tokenization(分词处理)
将输入内容分解为更小的片段 -
Prediction(概率预测)
计算可能出现的下一个词汇的概率(这些概率会受到 temperature 影响) -
Sampling(采样)
根据这些概率选择 token

Temperature 的影响:
- 低温(接近 0):Claude 变得极为确定性,几乎总是选择概率最高的 token
- 高温(接近 1):概率更均匀地分布在各个选项中,产生更多样化且富有创意的输出

结构化输出解决方案:助手消息预填充 + 停止序列
概念说明
消息预填充:让 Claude 以为自己已经说了填充的那些话,从而引导其输出方向。
示例:
- 直接问”面包和馒头哪个好吃”:Claude 大概率会输出中肯的答案
- 预填充”面包好吃,因为”:Claude 会以为自己已经说了这些话,并沿着引导继续生成
实际问题
默认情况下,当要求 Claude 生成 JSON 时,可能会得到:
{ "source": ["aws.ec2"], "detail-type": ["EC2 Instance State-change Notification"], "detail": { "state": ["running"] }}This rule captures EC2 instance state changes when instances start running.
JSON 格式正确,但被包裹在 Markdown 格式中并包含解释性文本,降低了用户体验的流畅度。
解决方案实现
messages = []add_user_message(messages, "Generate a very short event bridge rule as json")add_assistant_message(messages, "```json")text = chat(messages, stop_sequences=["```"])工作原理:
- 用户消息告诉 Claude 需要生成什么内容
- 预填充的助手消息让 Claude 以为它已经开始了一个 markdown 代码块
- Claude 直接续写 JSON 内容
- 当 Claude 试图用三个反引号关闭代码块时,停止序列立即终止生成
这样就能获得纯净的 JSON 输出,无需额外的格式处理。
第二部分:提示工程与评估
什么是提示工程?
提示工程 (Prompt Engineering) 是通过设计和优化输入提示 (Prompt),从而引导大语言模型 (LLM) 生成更准确、更相关、更高质量输出的技术。
简单来说,相比于随意的提问,一个结构化、清晰具体的提示词能让模型更好地理解你的意图,从而给出更出色的回答。
那么,如何科学地判断一个提示词是否优秀呢?这就引出了系统化的提示词评估。
提示词评估工作流
评估提示词表现遵循一个清晰的迭代流程,可以简单分为三个步骤:

-
生成测试数据集
将需要测试的提示词模板与一系列不同的问题或变量结合,批量发送给 Claude,并收集所有响应,形成评估的基础数据集。 -
执行评估
使用预设的评价器 (Grader) 对每个响应进行打分。评价器会根据特定标准(如格式是否正确、回答是否相关)来判断输出质量。 -
分析与优化
分析评估分数,找出表现不佳的案例。根据这些反馈优化提示词,然后重复前两个步骤,直到获得满意的平均分数。
三种核心评价器 (Graders)
为了自动化地执行评估,我们可以使用不同类型的评价器。
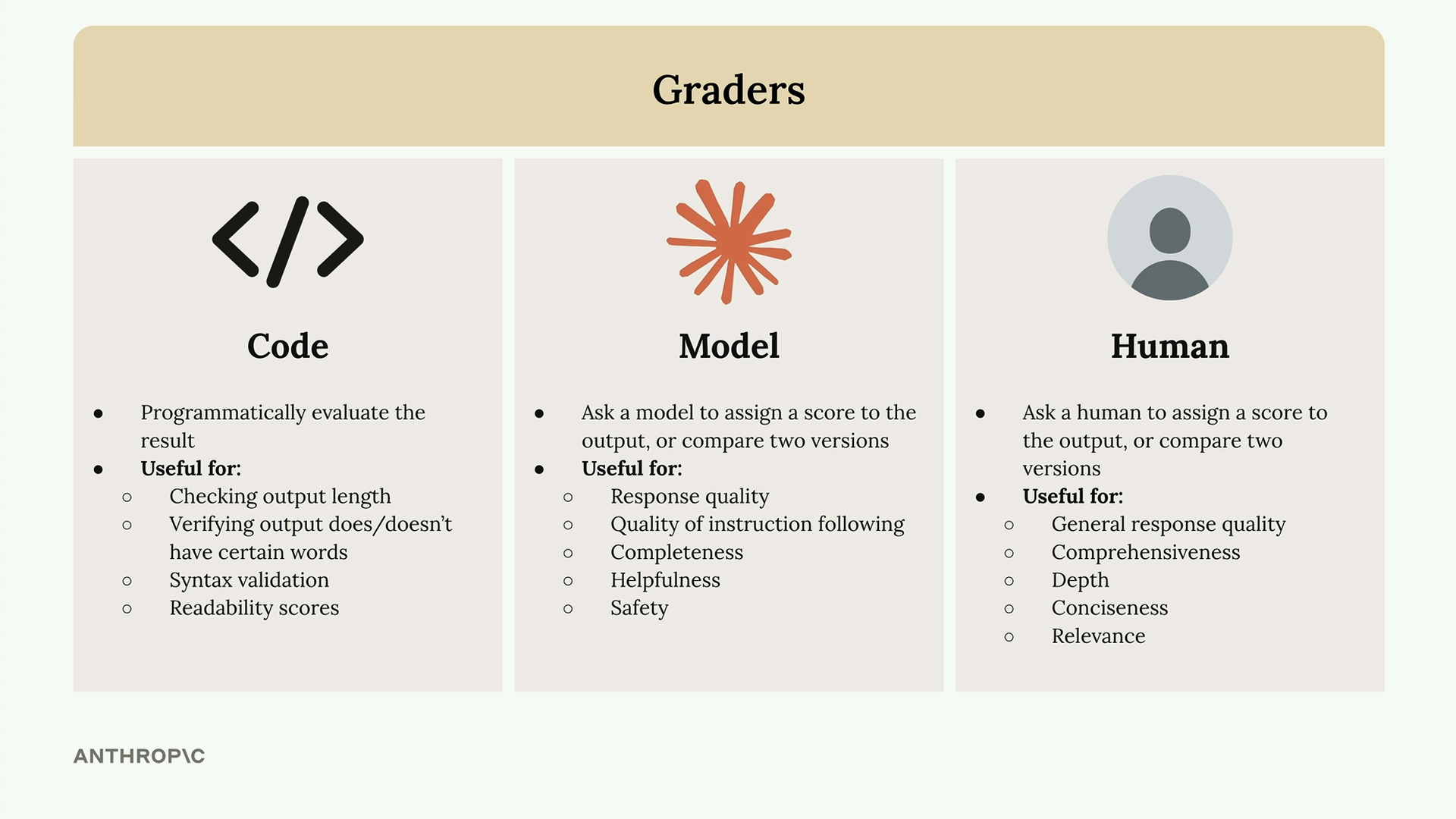
1. 代码评价器 (Code Graders)
代码评价器通过编写程序来检查模型输出是否符合特定规则,适用于客观、明确的评估任务。
常见用途:
- 检查输出的长度
- 验证是否包含或不包含特定关键词
- 对 JSON、Python 代码或正则表达式进行语法验证
实现示例:语法验证
以下函数通过尝试解析输出来验证其语法是否正确。如果解析成功,返回满分10分;如果失败,则返回0分。

def validate_json(text): try: json.loads(text.strip()) return 10 except json.JSONDecodeError: return 0
def validate_python(text): try: ast.parse(text.strip()) return 10 except SyntaxError: return 0
def validate_regex(text): try: re.compile(text.strip()) return 10 except re.error: return 02. 模型评价器 (Model Graders)
模型评价器将原始输出和评估任务再次发送给另一个大语言模型(如 Claude),利用模型本身的能力进行更主观、更复杂的评估。
适用场景:
- 回答的质量与帮助性
- 指令遵循的准确度
- 内容的完整性与安全性
实现示例:结构化评估
为了避免模型只给出一个模糊的分数(如6分),我们可以要求它提供结构化的 JSON 输出,从而增加评估的透明度。
def grade_by_model(test_case, output): # 创建评估提示词 eval_prompt = """ You are an expert code reviewer. Evaluate this AI-generated solution.
Task: {task} Solution: {solution}
Provide your evaluation as a structured JSON object with: - "strengths": An array of 1-3 key strengths - "weaknesses": An array of 1-3 key areas for improvement - "reasoning": A concise explanation of your assessment - "score": A number between 1-10 """
messages = [] # 此处假设 add_user_message 等函数已定义 add_user_message(messages, eval_prompt.format(task=test_case, solution=output)) add_assistant_message(messages, "```json")
eval_text = chat(messages, stop_sequences=["```"]) return json.loads(eval_text)这样,我们不仅得到一个分数,还能了解打分的具体依据(优点、弱点和推理)。
3. 人工评价器 (Human Graders)
人工评价是最灵活也是最耗时的方法,适用于评估机器难以判断的细微差别。
适用场景:
- 整体回答质量
- 内容的深度与全面性
- 表达的简洁性与关联性
这个简单,我是这个接口的实现类QAQ
